



We put the latest Apache Syncope and PostgreSQL on the bench to try and push to the limit: here are the results

Lately, some activity on the Apache Syncope project arose around the effort to improve the overall performance, with specific target of managing millions of identities.
While building a brand new persistence layer based on no-sql repositories is certainly possible - a non-trivial effort, anyway - immediate action was taken to enable the existing JPA-based persistence layer with the latest features provided by the supported DBMSes: PostgreSQL was the first one.
Coming from a long story in the Open Source world, PostgreSQL has become quite a hot topic in the recent years, and for several good reasons: compliance with SQL standards, strong performance, PL/PgSQL stored procedure calls, extensibility, replication, active community, enterprise support available by several trusted providers all around the world.
Among the features provided by PostgreSQL, the JSONB data type was identified as base for performance improvement for Apache Syncope.
Test code
The test code was developed as an Apache Maven project, and made available on GitHub. The project is set to accept several parameters to adjust its behavior, in order to be fully replicable.
An Apache JMeter suite is run, which performs concurrent operations against the Apache Syncope deployment: user create, read, search update, delete.
The suite was configured for 10 concurrent threads, each running all the operations for 30 loops, with ramp-up time of 10 seconds, for a total duration of 20 minutes.
Environment
- Apache Syncope 2.1.3-SNAPSHOT
- PostgreSQL 11.1
- Apache Maven 3.6.0
- Docker CE 5:18.09
- Oracle JDK 1.8.0_191
- Ubuntu 18.04
- Standard_F4s Azure VM - 4 CPU cores, 8 GB RAM
Please consider that no tuning nor optimization was performed: the Docker images for PostgreSQL and Elasticsearch are vanilla from DockerHub.
Results
The test suite was run under different conditions, and the results are now public at https://tirasa.github.io/syncoperf/:
- number of pre-existing users in the database: 1,000, 10,000, 100,000 and 1,000,000 (JSONB only)
- definition of dynamic conditions for group membership: given the considerable overhead needed by this feature, it was included only for smaller sets (1,000 and 10,000); label nodyn was used to identify the absence of dynamic memberships
- availability of the Elasticsearch extension: with bigger sets (100,000 and 1,000,000) there is practically no brain in running without such support enabled; label es was used to identify that Elasticsearch was used
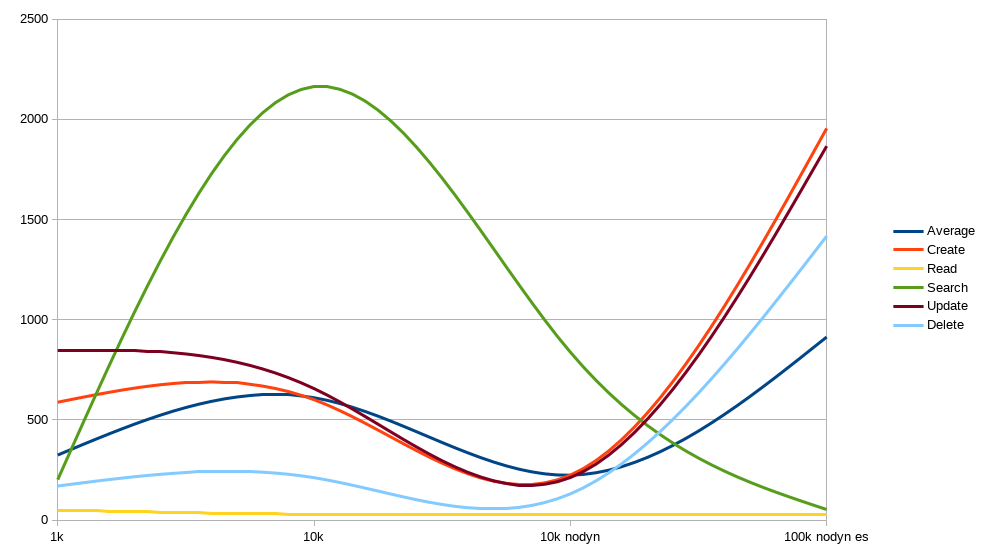
PostgreSQL 11.1, standard JPA persistence
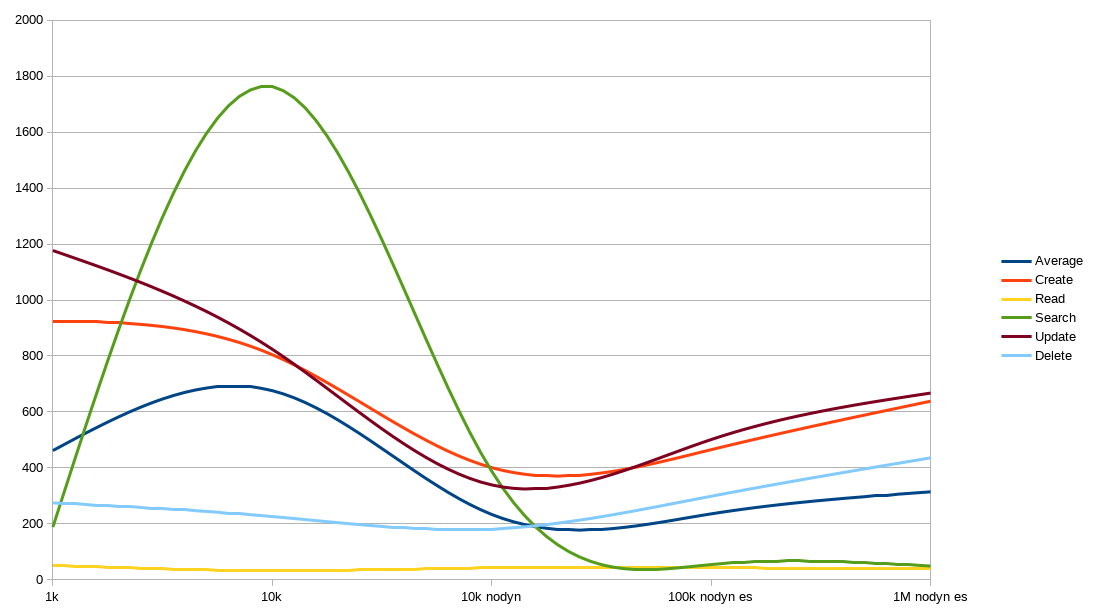
PostgreSQL 11.1, JPA persistence with JSONB support
Considerations
Thanks to PostgreSQL and JSONB, Apache Syncope is able to gracefully manage millions of identities, with reasonable response times and throughput.
For smaller sets, standard persistence works quite well, even slightly better than JSONB; for larger sets there is simply no comparison: JSONB is the clear winner.
Given the high response times with standard JPA persistence for 100,000 identities, there were no enough reasons to check 1,000,000.
There is absolutely no reason not to empower Elasticsearch when the number of identities goes above 10,000 - see the difference between "10k nodyn" and "100k nodyn es" in both figures above, especially since the number of identities in the latter case is ten times the former.
Dynamic memberships are extremely resource-demanding and should be used with great care.
 Good
Good
